Aurélien Francheteau
Brice Francois
Sébastien Helbert
Jérôme Limousin
Jean-Philippe Wilsch
Projet de DESS Génie Informatique
CorbaTrace
Outils d'observation pour applications réparties utilisant CORBA
Faculté des
Sciences et Techniques
Université de
Nantes
Année 2002/2003
Responsables
: Philippe Lamarre
Christian
Attiogbé
Remerciements
Nous remercions messieurs Philippe Lamarre
et Christian Attiogbé pour leurs conseils et leur encadrement durant notre
travail.
Nous tenons également à remercier Etienne
Juliot, responsable de CorbaTrace lors de l’année précédente, dont l’aide du
début jusqu'à la fin du projet nous a été très précieuse.
Sommaire
2.1.1 Logs
distants : CorbaTrace
2.2.1 Création
du fichier de journal (Logs)
3.1 Pourquoi utiliser Java Logging ?
3.1.1 Principe de Java Logging
3.1.2 Utilisation de Java Logging
3.2 Choix et modifications effectuées
3.2.2 La table
de correspondance
3.2.3 Nouvelle
DTD pour les Logs
4 Synchronisation des messages
4.5 Processus de synchronisation
4.5.1 Ajout des
messages logués dans le graphe.
4.5.2 Estimation
des décalages d’horloge
4.5.3 Mise à jour des messages
5.1 Analyse - Choix technologiques
5.1.1 Description des classes.
5.2 Présentation de l'interface graphique
6 Diagrammes de séquence et SVG
6.1 UML et les diagrammes de séquence
6.3.1 La
génération de fichiers SVG
6.3.2 Le contenu du fichier SVG
6.4 Description de l'API
SequenceDiagram
6.4.2 Le paquetage spécifique à CorbaTrace
7.2.1 Diagrammes de Séquence en SVG
Introduction
Dans ce rapport, nous présentons le travail réalisé cette année sur CorbaTrace, logiciel comprenant un ensemble d’outils d’observation pour le débogage d’applications réparties utilisant CORBA.
Ce logiciel a, dans sa première version, été développé par des étudiants du DESS au cours de l’année 2001/2002. Son but est d’intercepter les échanges de messages sur le bus CORBA, de les enregistrer sous forme de fichiers de logs, puis de traiter ces logs, pour finalement pouvoir en afficher la trace sous forme de diagrammes de séquence. Toutefois cette version présentait des limitations. Tout d’abord les appels de méthodes entre objets locaux n’étaient pas interceptés. Or un appel étant en fait un envoi de message entre deux objets, ils pourrait être utile de les logger pour visualiser les echanges d’informations entre objets. De plus la synchronisation des dates dans les messages interceptés était peu efficace dès lors que les horloges des systèmes répartis étaient désynchronisées. L’ancienne version nécessitait l’utilisation d’un atelier de génie logiciel pour visualiser les diagrammes de séquence générés au format XMI[1] rendant ainsi l’application dépendante d’autres outils, chose parfois très contraignante. Enfin l’aspect austère de l’utilisation du logiciel via la ligne de commande rend l’application difficile d’accès à un utilisateur débutant.
A partir de ces constatations, il nous est demandé cette année d’améliorer le logiciel en travaillant sur plusieurs points. L’utilisation de l’API[2] Java Logging permettra l’interception des messages entre objets locaux et également une interception asynchrone. Il sera nécessaire d’évaluer la qualité actuelle de la synchronisation afin de faire une refonte de l’algorithme en conséquence. Nous devrons réaliser un mécanisme de génération de diagrammes de séquence dans un format nous permettant de les visualiser facilement et fournir un outil de visualisation inclus dans CorbaTrace. Pour terminer nous allons réaliser une interface graphique permettant d’accéder facilement et intuitivement aux principales fonctionnalités de CorbaTrace.
L’objectif est d’obtenir une version complète et
stable, d’offrir une distribution accessible à tout programmeur CORBA, et
fournir quelques exemples d’applications utilisant CorbaTrace. Dans ce rapport,
nous allons tout d'abord détailler le cahier des charges qui nous a été confié.
Nous aborderons ensuite Java Logging et la synchronisation des messages.
Puis nous présenterons l'interface graphique du logiciel, ainsi que la
conception de l'API créée spécialement pour tracer des diagrammes de séquence
en fonction des fichiers de logs. Nous terminerons enfin par des tests et
l'intégration de CorbaTrace dans un environnement Linux ou Windows.
1 Historique
1.1 CORBA
Les applications distribuées sont très difficiles à
déboguer : le programme utilisant plusieurs machines, maîtriser les
échanges d’informations et les accès distants est très complexe. C’est le cas
en particulier des applications CORBA.
CORBA
est l'acronyme de Common Object Request Broker Architecture,
autrement dit, Architecture Standardisée d'un Négociateur de Requêtes sur des
Objets. C'est la solution apportée par l'OMG (Object Management
Group) au besoin d'interopérabilité face à la prolifération des machines
et des logiciels disponibles sur le marché.
Ses principales fonctionnalités
sont :
· La transparence : par rapport au système d’exploitation, au langage de programmation, à la localisation des objets
· CORBA est orienté objet : les principes fondamentaux de la programmation objet sont présent : encapsulation, polymorphisme, héritage et instanciation
· CORBA est orienté services : de nombreux services sont proposés par la norme CORBA pour faciliter son utilisation : nommage, vendeur, événement, notification, …
Nous ne nous étendrons pas plus sur CORBA, de
nombreuses présentations existent sur Internet et ce n’est pas le but de ce
rapport.
1.2 CorbaTrace v0.1
CorbaTrace fut à l'origine un projet de maîtrise intitulé
"Outils d'observation pour une application répartie : société BONOM",
réalisé par Vincent Tricoire et Frédéric Breton. Il consistait en la réalisation d'outils d'interceptions de messages
circulant entre divers objets d'une application répartie utilisant CORBA, et
d'outils de visualisation de ces échanges.
L'interception des messages utilisait les intercepteurs portables spécifiés dans la norme CORBA 2.3. Ces intercepteurs, créés sur le bus CORBA, sont indépendants du langage utilisé pour la création des objets et permettent l'interception de l'émission et réception des messages ou d'exception. Les messages interceptés sont enregistrés dans des fichiers journaux. Un fichier journal est crée par objet. Les informations récupérées par les intercepteurs sont l'émetteur et le destinataire du message, un identifiant de message, la date précise d'interception et le contenu du message.
La réalisation des diagrammes de séquence était faite grâce à un paquetage LaTeX. Son utilisation était peu aisée, notamment à cause du fait que les messages n'étaient représentés par une date mais par des décalages de temps.
Plusieurs difficultés s'étaient posées aux deux étudiants durant leur travail, dont :
ü Des problèmes lors de l'identification des clients et des messages (la méthode employée de mettre l'identifiant des objets en paramètre des méthodes était très contraignante)
ü Des problèmes de date dans les messages, les différents objets pouvant avoir des horloges décalées, contrairement à l'hypothèse choisie par les étudiants de même heure pour tous. Il faut pouvoir synchroniser les horloges.
ü
Enfin la forme textuelle brute des fichiers de
logs et l'utilisation de LaTeX pour le diagramme de séquence ne sont pas
satisfaisant. Il serait préférable d'utiliser XML pour l'enregistrement des
messages, qui permettrait plus facilement l'application de filtre et la
génération de fichier XMI, format permettant d'obtenir une représentation
graphique d'un diagramme de séquence dans un atelier de génie logiciel.
1.3 CorbaTrace v1.0
Le projet fut repris l'année suivante par cinq étudiants de DESS Génie Informatique. L'objectif était de réaliser une interception moins contraignante et une visualisation plus performante.
L'interception
utilise toujours les intercepteurs portables. Des points d'interceptions ont
été définis du coté client et du coté serveur :
ü
Coté client
§
send_request (envoi de requête vers un serveur)
§
send_poll (envoi d'une demande d'information au serveur)
§
receive_repply (réception d'une réponse)
§
receive_exception (réception d'une exception)
§
receive_other (réception d'un message qui n'est ni une réponse ni
une exception)
ü
Coté serveur
§
receive_request (réception d'une requête)
§
receive_request_service_context (lors de la réception d'une requête, ce point permet
de récupérer le ServiceContext, qui permet de passer des informations de
l'application hôte aux intercepteurs, de l'intercepteur du client à
l'intercepteur du serveur et vice-versa)
§
send_reply (envoi d'une réponse à une requête)
§
send_exception (envoi d'une exception)
§
send_other (envoi d'autre chose qu'une réponse ou une exception)
Les fichiers journaux (nous parlerons de Logs) sont désormais enregistrés sous forme de fichiers XML, format aujourd'hui reconnu dans le domaine de la gestion de données. Ce format, en plus de permettre une lecture humaine aisée, facilite le traitement des fichiers par l'application, grâce à des API prévues pour cela telles que SAX.
Une DTD a été définie pour ces Logs, afin de garantir leur validité. Cette DTD décrit également la forme des filtres, eux aussi au format XML, permettant de sélectionner les informations à afficher dans le diagramme de séquence final.
La partie du programme réalisant cette transformation de fichiers de Logs en diagramme de séquence se nomme Log2XMI. Elle intègre notamment un mécanisme de synchronisation des messages répartis sur des systèmes qui peuvent êtres différents. Celui-ci fonctionne en se basant sur un objet de référence puis en recalculant les dates locales des autres objets par rapport à la date locale de l'objet de référence. Log2XMI intègre également comme dit auparavant un mécanisme de filtrage.
Un diagramme de séquence est donc généré au format XMI, pouvant être lu par des outils de génie logicielle.
L’évolution principale du projet fut sa diffusion sur
Internet. Conscient de l’intérêt que ce travail pourrait attirer, l’équipe a
publié CorbaTrace sous licence LGPL[3]
sur le site http://corbatrace.tuxfamily.org.
De nombreuses réactions positives ont été reçues et le site est
fréquenté par des utilisateurs de pays tels que l’Allemagne, le Japon ou
2 Cahier des charges
2.1 L'existant
Dans cette partie du rapport, nous énonçons le travail
déjà réalisé une année auparavant et cela pour mieux comprendre le travail
effectué cette année. Pour ceux qui souhaiteraient approfondir cette prise de
connaissance, il est conseillé de lire le rapport de l’année passée.
2.1.1
Logs
distants : CorbaTrace
Les logs distants sur des objets Corba, se base sur des standards de l’OMG sur les intercepteurs. En effet depuis la norme Corba 2.3, une méthode d’interception sur les ORBs a été standardisée. L’interception peut se dérouler sur plusieurs actions : l’émission d’un message, la réception d’un message ou lorsqu’une exception est levée. Les intercepteurs se placent sur le bus Corba et donc sont totalement transparents pour l’application. L’application peut elle par contre agir sur ces interceptions (les autoriser ou non). La figure1 montre l’architecture globale de l’interception :
Figure 1: Les intercepteurs vus par l’OMG

Figure 1 :
Les intercepteurs vus par l’OMG
Au sein du POA et de l’ORB, l’interception n'est qu’une politique particulière. Un degré d’interception est donc réglable au niveau de chacun. Le degré 0 n’intercepte rien, par contre le degré 1 est suffisant pour intercepter des informations utiles au déboguage.
En ce qui concerne Corbatrace, des classes spécifiques à l’interception ont été surchargées ou encapsulées de manière à minimiser le nombre de changements nécessaires à apporter à une application pour logger les communications entre les différentes parties. Les intercepteurs s’enregistrent auprès de l’ORB via ces classes. L’activation de l’intercepteur est par contre différente suivant qu’il est fait du coté client ou du côté serveur. Une fois l’intercepteur enregistré, il faut le placer sur le bon composant. Pour le cas du client il est mis sur l’ORB, par contre pour le cas du serveur il est mis sur le POA. Une fois que l’intercepteur est placé sur le POA, un autre POA est créé dynamiquement avec les intercepteurs activés à partir d’un POA existant dans l’application cliente (rootPOA). La figure 2 représente des intercepteurs vus de l’application Corbatrace.
Figure 2: Les intercepteurs vus par CorbaTrace


Figure 2: Les
intercepteurs vus par CorbaTrace
Après toutes ces initialisations, dans le cas client, on peut utiliser l’objet métier directement. Par contre pour le cas serveur, en plus d’utiliser l’objet métier, il faut positionner l’objet métier servant sur le nouveau POA créé dynamiquement par la classe IntercepteurServeur. Pour plus d’information sur ce sujet vous pouvez vous reporter au rapport du projet Corbatrace V1.0.
Comme nous l’avons énoncé précédemment, plusieurs actions sont possibles à intercepter. L’envoi d’une requête implique grâce au mécanisme d’interception initialisé, la mise en route de celui-ci. L’interception se fera du coté client (send_request). La requête sera ensuite interceptée du coté serveur en deux étapes, la première (receive_request_service_context) qui permet de récupérer les informations de l’émetteur de la requête. Ensuite il y a l’interception effective de la réception de la requête (receive_request). Une fois la requête exécutée au niveau du serveur, il y a une interception de l’envoie de la réponse (receive_request) et enfin une interception au niveau du client de la réception de la réponse (receive_reply). Si l’exécution de la requête lève une exception par le serveur, l’envoie de cette exception au client sera interceptée au niveau serveur (send_exception) puis à sa réception au niveau client (receive_exception). Le client peut aussi envoyer un type de requête particulier. Il consiste en une demande d’informations du client sur l’état du servant ou sur l’ORB. Ce type de demande sera intercepté au niveau client (send_poll), par contre pour la suite cette demande sera traitée comme toutes les autres requêtes. Il y a enfin un dernier type d’interception, l’envoie côté serveur (send_other) et la réception côté client (receive_other) de tout autre chose qu’une réponse de requête ou une exception.
Voici un schéma récapitulatif des différents types d’interception :
receive_request Figure 3: Les points d’interception Client Servant send_request send_poll receive_reply receive_exception receive_other receive_request_service_context send_reply send_exception send_other
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Figure 3 :
Les points d’interception
Une fois les interceptions générées, il faut traiter les informations qu’elles produisent.
2.1.2
Log2XMI
Pour exploiter les fichiers de logs issus des interceptions de CorbaTrace, l'application Log2XMI a été réalisée. Elle réalise la transformation des fichiers de logs, au format XML, en un seul fichier au format XMI, une DTD standardisée par l'OMG, pouvant être utilisée pour représenter des diagrammes de séquences, forme sous laquelle vont être représentés les échanges de messages dans l'application CORBA loguée.
5 étapes distinctes composent le
processus de transformation de Log2XMI :
§
Le parsage des fichiers de logs, contenants uniquement des
demi-messages, c'est à dire les informations sur uniquement l'envoi ou la
réception d'un message.
§
La fusion des demi-messages, pour obtenir un message complet
à partir de deux demi-messages correspondant.
§
La synchronisation des messages, pour corriger les
différences issues de décalage entre les horloges des différents hôtes des
objets de l'application CORBA loguée.
§
Le filtrage des messages, pour faire apparaître sur le
diagramme de séquence uniquement les informations que l'utilisateur juge
pertinentes.
§
La création du fichier XMI, à partir des messages filtrés
2.1.3
La
synchronisation
Dans sa première version, Corbatrace était déjà doté d’une synchronisation des messages logués, partie essentielle du logiciel sans laquelle toute visualisation d’une trace aurait été très peu compréhensible et donc sans intérêt.
La principale difficulté vient des différences entre les horloges d’objets distants.
Les programmeurs avaient alors posé leur
problématique et envisagé une technique de synchronisation y répondant, avant
d’implémenter leur solution.
Dans la problématique, l’hypothèse est faite que les
messages sont instantanés et le traitement des messages est proposé.
La technique de synchronisation envisagée comporte
trois étapes successives:
Ø
l’ajout des
messages logués
Ø
l’estimation des
décalages d’horloges
Ø
la génération
des messages séquentialisés
L’implémentation a aboutit bien qu’elle eut pu être
améliorée (notamment dans la deuxième des étapes énoncées ci-dessus).
2.2 Apports nécessaires
2.2.1
Création
du fichier de journal (Logs)
La version 1.0 de CorbaTrace utilisait la classe IndentString du package corbatrace.utils pour enregistrer des Logs au format XML dans un « buffer » pour ensuite écrire son contenu dans un fichier de Log.
Cette manière de procéder a de nombreux désavantages. D’abord, les performances de l’intercepteur sont réduites. En effet, à chaque interception sur le bus CORBA, les informations obtenues sont stockées dans des objets de type XMLLog qui sont transformés au format XML au moment de l’écriture dans le fichier de Log. Or cette transformation est coûteuse en temps, d’autant plus que XML à pour caractéristique d’être « verbeux ». De même l’écriture dans le fichier de log nécessite une ouverture de fichier, un positionnement en fin de fichier, l’écriture du flux XML dans ce fichier, puis sa fermeture. Autant d’opérations qui sont bien connues pour êtres coûteuses en temps. Ainsi durant toutes ces opérations l’application contenant les intercepteurs est bloquée. Même si ce temps reste relativement faible, il ne faut pas oublier que CorbaTrace est un notamment un outil de déboguage et se doit de fournir les informations les plus précises que possibles en ce qui concerne la succession des évènements dans le temps.
De plus si l’intercepteur s’interrompt de manière brutale
lors de l’écriture du « buffer », les fichiers générés seront
invalides. Comme nous venons de la préciser CorbaTrace est un outil de
déboguage, les applications qui l’utilisent sont donc potentiellement plus
sujettes à la possibilité de terminaison inattendue du programme que d’autres.
Si cela se produit alors que l’intercepteur écrit dans le fichier de Logs, le
fichier risquera d’être invalide (non respect de
Pour ces deux raisons nous avons besoin d’un mécanisme asynchrone qui se charge de formater les Logs et de les écrire dans un fichier indépendamment de l’application contenant les intercepteurs. Nous allons donc déléguer cette tâche à un package spécialement conçu pour cela, intégré depuis la version 1.4 de Java, le package JavaLogging.
2.2.2
Synchronisation
Cette présentation des apports envisagés pour la
synchronisation est un préambule au chapitre qui lui est consacré (chap. 5).
Les modifications réellement effectuées (ou à effectuer) découlant de notre
analyse, sont énoncées et détaillées dans ce chapitre.
Etant donné que
la nouvelle version de Corbatrace ne se contente plus de gérer le seul cas des
logs Corba, mais s’intéresse désormais également aux logs locaux, il s’agit
d’étudier ce nouveau cas: nécessite t’il des modifications dans la
synchronisation? Nous allons donc effectuer une phase d’analyse, suivie des
éventuels apports nécessaires.
Il s’avère aussi que l’implémentation de la technique
de synchronisation, bien qu’étant réalisée, comportait de légères lacunes
particulièrement lorsque les horloges des différents systèmes répartis n’étaient
pas en concordance, qu’il s’agit maintenant de combler. Un affinage de
l’estimation des décalages d’horloge était d’ailleurs proposé dans le rapport
de l’année précédente.
Un autre travail envisagé serait de reconsidérer les
hypothèses de départ. Ce serait d’abord un sérieux travail d’analyse, qui
signifierait surtout en cas de nouvelles hypothèses de travail de reprendre une
grande partie du code réalisé pour le mettre à jour. Nous serions tout de même
fortement intéressés par la gestion du parallélisme qui semble malheureusement
avoir été laissée de côté.
Dans tous les cas, il est nécessaire de rependre le
code afin de l’améliorer. Les méthodes de refactoring permettraient de
le rendre plus clair, plus accessible et ainsi plus facile à modifier.
2.2.3
Interface
graphique
Nous avons
également constaté qu'un frein au développement de CorbaTrace auprès d'un plus
grand public pouvait être une certaine difficulté d'approche et de démarrage du
logiciel, comme par exemple le fait que l'application ne fonctionne uniquement
via la ligne de commandes.
Afin de mettre
CorbaTrace à la portée de plus de personnes, une solution pouvait être de
réaliser une interface graphique accompagnant le logiciel. Cette interface
proposerait une aide notamment pour l'utilisation de l'application Log2XMI, en
proposant par exemple :
Ø
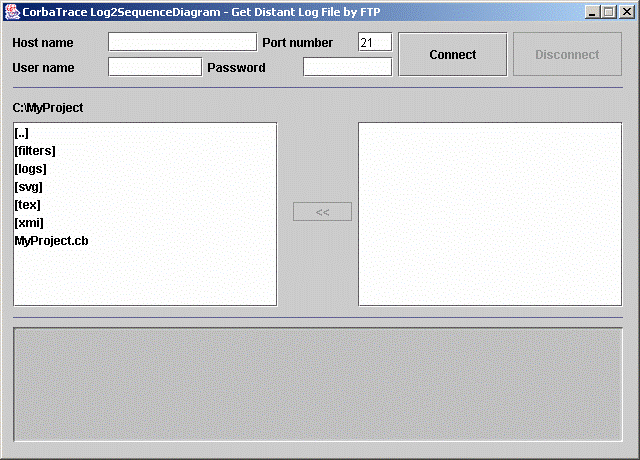
De pouvoir récupérer des fichiers de logs situés sur des
machines distantes, cas pouvant être fréquent puisque CorbaTrace propose
d'aider au débogage d'applications CORBA, donc pouvant être réparties.
Ø
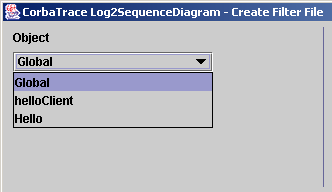
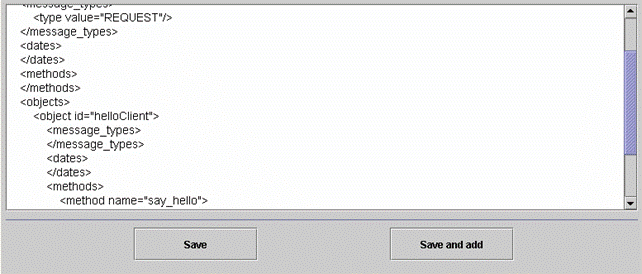
D'aider à l'écriture de fichiers de filtres. Ces fichiers
devaient auparavant être écrits à la main. L'interface proposerait à
l'utilisateur de générer le fichier XML de filtre à partir d'informations
sélectionnées dans des menus déroulant, très simples d'utilisation.
Ø
D'utiliser Log2XMI plus facilement, simplement en
sélectionnant les fichiers de logs, le fichier de filtre et les options que
l'utilisateur désirent pour générer un diagramme de séquence avec des listes,
des cases à cocher, des widgets graphiques très simples à utiliser.
Ø
Permettre à l'utilisateur de visualiser ses diagrammes de
séquence sans recours à un logiciel externe en proposant un visualiseur de
fichier SVG
Pour garder l'aspect important de portabilité de
CorbaTrace grâce à l'utilisation du langage Java, l'interface graphique sera
développée grâce à la librairie Swing, l'API graphique de Java [12].
2.2.4
Diagrammes de
séquence
La précédente version du projet génère des diagrammes
de séquences sous la forme de fichiers XMI. Cela permettait un affichage des
diagrammes dans les logiciels de modélisation UML tel que Poseidon for
UML [1], Rational Rose [2] ou MagicDraw UML [3]. L’ancienne
application peut également convertir les fichiers XMI en fichier TeX affiché
sous LaTeX [4].
L’inconvénient majeur de ces choix est qu’il faut
soit disposer d’un logiciel de modélisation UML alors que l’on veut simplement
afficher un diagramme et non le modéliser ou soit visualiser le diagramme sous
LaTex qui donne un résultat médiocre la librairie fournie étant trop limitée
pour répondre à nos besoins. En plus d’être inadaptées aux besoins, ces
solutions sont peu portables (tout le monde ne dispose pas d’outils de
modélisation UML ou de LaTeX).
Il nous a donc
semblé important d’utiliser un autre outil de visualisation plus adapté. Nous
nous sommes tournés vers SVG [5] et en expliquons les raisons dans la partie 6
du rapport.
3 Java Logging
3.1 Pourquoi utiliser Java Logging ?
3.1.1 Principe de Java Logging
Les applications font des appels de méthodes sur des Objets de la classe Logger. Ces objets créent des enregistrements de Logs, les LogRecord qui sont envoyés aux objets de la classe Handler pour être publiés. Les objets de la classe Logger et Handler peuvent utiliser des niveaux pour filtrer les Logs suivant leur importance. Ce sont les objets de type Filter qui se chargent de filtrer les Logs. Enfin, les objets de type Handler peuvent utiliser des instances de Formatter pour mettre en forme le flux de sortie.
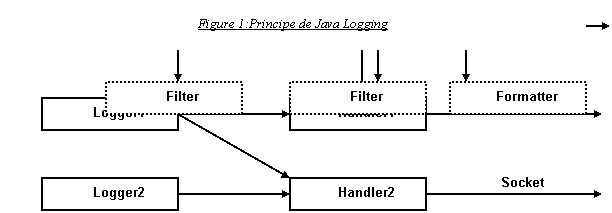

Chaque Logger peut posséder plusieurs Handler. Les Handler peuvent êtres organisés de façon hiérarchique et répercuter la publication des Logs aux Handler de niveaux supérieurs.
Seul le traitement du Logger est bloquant pour l’application. Le Logger doit être conçu de façon à minimiser le coût et le temps avant de transmettre aux Handler les enregistrements de Logs, qui eux, appartiennent à un autre processus que celui de l’application. Les opérations les plus coûteuses telles que la localisation de la sortie pour le flux et son formatage sont donc prises en charge par les Handler de façon asynchrone afin d’optimiser les performances de l’application.
3.1.2 Utilisation de Java Logging
Nous devrons étendre la classe Logger pour permettre par le simple appel de méthodes statiques sur cette classe de loguer des informations. Nous n’aurons pas recours aux filtres.
Nous ne pouvons pas utiliser le formateur XML proposé par défaut par Java 1.4 pour deux raisons. La première est que ce formateur logue des enregistrements de type LogRecord qui contiennent des informations telles que la date, un numéro de séquence un identifiant de Thread émetteur, etc. qui sont soit redondantes par rapport aux informations que nous disposons déjà, soit superflues (en tous cas pour le moment). Le seconde raison est qu’il autorise de loguer une chaîne de caractères dans un champ message, mais les caractères spéciaux XML que peut contenir cette chaîne seront déspécialisés avant l’émission du flux de sortie.
Ce qui implique lors de la lecture du fichier de Logs de
parser chaque Log Java pour récupérer les informations Corba qu’ils contiennent
avant de les convertir au format XML pour de nouveau les parser, donc deux DTD
seront nécessaires, etc. Cette solution n’est pas envisageable. Nous
choisissons de surcharger
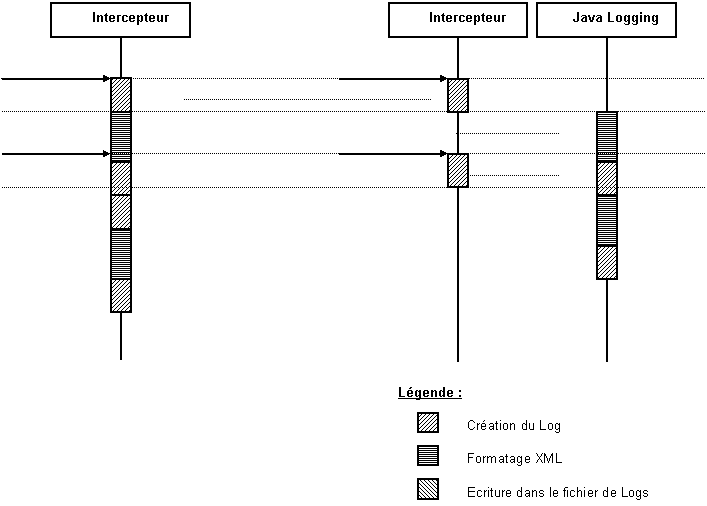
Figure 6 : Interception
3.1.2.1 CorbaTrace Logger : Clogger
Cette classe surcharge La classe Logger de JavaLogging et fourni un ensemble de méthodes permettant d’enregistrer les Logs distants propres à CORBA mais aussi des Logs locaux. De plus c’est auprès de cette classe que se feront les associations identifiant Objet/Nom d’objet dont nous reparlerons plus tard (cf. "3.2.2 La table de correspondance"). Les signatures des méthodes sont les suivantes :
public static void clearNames();
public static String setName(Object
object, String name);
public static String getName(Object
object);
public static void
logCallBegin(String loggerName, Object src, Object dest,
String method, String[] args);
public static void logCallEnd(String
loggerName, Object src, Object dest,
String method, String result);
public static void
logActivityBegin(String loggerName, Object obj);
public static void
logActivityEnd(String loggerName, Object obj);
public static void logTrace(String
loggerName, Object obj, String message);
public void log(LogRecord record);
Les trois premières méthodes permettent de manipuler la table de correspondance dont nous avons parlé précédemment, les cinq suivantes concernent les Logs locaux et permettent, respectivement de déclarer l’appel d’une fonction, la fin de son exécution, le début d’activité d’un thread, la fin de son activité et enfin de construire un log de trace. La dernière méthode est utilisée par les intercepteurs CORBA qui construisent eux même leur propre Log, le CLogRecord.
Remarque : Tous les Logs CorbaTrace sont générés via la méthode "log" de cette classe. En effet, les méthodes de création de Logs locaux créent en fait une nouvelle instance de la classe CLogRecord, modifient les attributs appropriés de l’enregistrement puis invoquent la méthode "log" en le passant en paramètre. Ceci permet notamment d’attribuer à chaque log un identifiant unique.
3.1.2.2 CorbaTrace LogRecord : CLogRecord
La classe CLogRecord étend la classe LogRecord du package JavaLogging. Elle permet de construire des objets dans lesquels peuvent êtres stockés toutes les informations enregistrées par les intercepteurs CORBA. Cette classe est donc très similaire à la classe XMLLog de CorbaTrace v1.0.
3.1.2.3 CorbaTrace XMLFormatter : CXMLformatter
La classe CXMLFormater étend
la classe XMLFormater du package JavaLogging. Elle permet de transformer un
objet de type CLogRecord au format XML correspondant à
3.2 Choix et modifications effectuées
3.2.1
Classe
IndentString :
La
classe IndentString qui se situe dans le package corbatrace.utils
à été étendue pour simplifier son
utilisation. Elle à pour but de créer une chaîne de caractères en permettant
une indentation correcte des balises XML de manière simple et performante.
L’indentation ayant pour seul intérêt de rendre plus aisée la lecture des informations des fichiers de Logs qui
n’apparaîtraient pas dans les diagrammes de séquences générés. Dans la version
1.0 de CorbaTrace cette classe proposait les quatre méthodes suivantes :
Ø
inc :
Incrémente le niveau d’indentation
Ø
dec :
Décrémente le niveau d’indentation
Ø
attribute :
Concatène le texte
Ø
newLine
: insère un saut de ligne
Ø
insert :
indente, insère le texte et passe à la ligne
Nous avons choisi d’étendre cette classe pour simplifier le code
nécessaire et donc limiter le nombre d’erreurs potentielles et rendre
transparente la gestion des indentations et des sauts de lignes.
Les méthodes ajoutées sont les suivantes :
Ø
openTag :
Ouvre une balise XML
Ø
closeTag :
Ferme une balise XML
Ø
attribute :
ajoute un attribut
Ø
beginTag
: insère une balise XML ouvrante
Ø
endTag
: insère une balise XML fermante
Ainsi pour obtenir le fichier XML suivant :
<personne>
<age>53</age>
<name first="Omer"
last="Simpson">
</personne>
le code nécessaire sera :
out.beginTag("personne");
out.beginTag("age");
out.insert("53");
out.endTag("age");
out.openTag("name");
out.attribute("first",
"Omer");
out.attribute("last",
"Simpsons");
out.endTag("name");
out.endTag("personne");
Les méthodes inc, dec, append et newLine deviennent obsolètes.
3.2.2
La table de correspondance
Lorsque des Logs sont générés nous leur attribuons
un identifiant unique correspondant à l’objet qui à émis le log. Cet
identifiant permettra par la suite au générateur de diagrammes de séquences de
pouvoir identifier les émetteurs et récepteurs de chaque Log.

Cependant
ces identifiants uniques correspondent à des entiers qui n’ont pas de
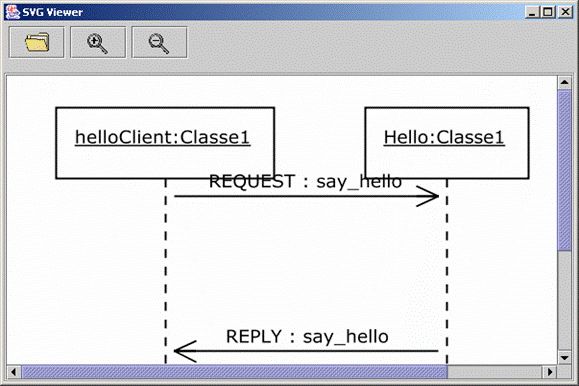
signification particulière pour l’utilisateur (cf. Figure 7). Il nous à donc fallu mettre en place un mécanisme
permettant au programmeur d’associer aux identifiants des objets émetteurs ou
récepteurs des noms (chaînes de caractères) que nous appellerons table de
correspondance.
Figure 7
: Exemple de diagramme sans table de correspondance
Pour associer un nom à un objet il suffit
d’invoquer la méthode statique setName de la
classe Clogger.
Ainsi en insérant le code nécessaire avant de
générer des Logs, le diagramme de séquence devient plus explicite (cf. Figure 8).

Figure 8
: Exemple de diagramme avec table de correspondance
Il est possible d’initialiser la table de
correspondance en utilisant la méthode Clogger.clearNames et de
retrouver le nom associé à un objet en invoquant la méthode Clogger.getName.
Evidement, il est à la charge du programmeur de s’assurer que les noms donnés
identifient les objets de manière unique, sans quoi le diagramme de séquence
généré risque d’être incohérent.
3.2.3
Nouvelle
DTD pour les Logs
L’ajout de Logs Locaux pour CorbaTrace v2.0 a
imposé la modification de
Les modifications apportées sont les
suivantes :
Ø
Le champ opération du champ message est rendu
optionnel. Ce champ n’étant pas nécessaire pour les Logs de début et de fin
d’activité.
|
CorbaTrace v1.0 |
|
CorbaTrace v2.0 |
|
<!ELEMENT message( local_object, distant_object?, operation, result?, options? )> |
à |
<!ELEMENT message( local_object, distant_object?, operation?, result?, options? )> |
Ø
L’attribut request_id du champ Message devient optionnel. Ce
champ qui identifie les requêtes sur le bus CORBA de manière unique, n’a pas de
signification pour les Logs locaux.
|
CorbaTrace v1.0 |
|
CorbaTrace v2.0 |
|
<!ATTLIST message mesg_id CDATA #REQUIRED request_id
CDATA # REQUIRED type CDATA
#REQUIRED > |
à |
<!ATTLIST message mesg_id CDATA #REQUIRED request_id
CDATA #IMPLIED type CDATA
#REQUIRED > |
Ø
Les attributs date et request_id du
champ distant_object deviennent optionnels. Le premier parce que pour
les logs locaux, on considère que le temps qui s’écoule entre l’appel de
méthode et le début de l’exécution de la méthode par l’objet est nul. Le second
pour la même raison que celle citée pour l’attribut request_id du
champ message.
|
CorbaTrace v1.0 |
|
CorbaTrace v2.0 |
|
<!ATTLIST distant_object id CDATA
#REQUIRED date CDATA
#REQUIRED request_id
CDATA #REQUIRED > |
à |
<!ATTLIST
distant_object id CDATA #REQUIRED date CDATA #IMPLIED request_id CDATA #IMPLIED > |
Ø
L’attribut inout du champ argument devient optionnel
puisqu’en Java tous les attributs d’appels sont considérés comme Entrée et
Sortie.
|
CorbaTrace v1.0 |
|
CorbaTrace v2.0 |
|
<!ATTLIST argument inout(in|out|inout)#REQUIRED name CDATA
#IMPLIED value CDATA
#REQUIRED type CDATA
#REQUIRED > |
à |
<!ATTLIST argument inout(in|out|inout)#IMPLIED name CDATA
#IMPLIED value CDATA
#REQUIRED type CDATA
#REQUIRED > |
3.2.4
Appel
de procédures
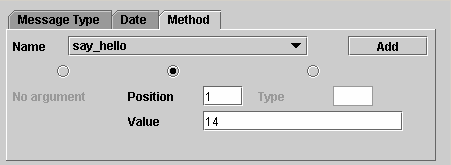
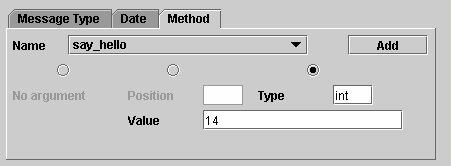
Le premier type de log local inclus dans l’application CorbaTrace est l’appel de procédure qui est constitué en fait de l‘appel de la méthode et de la fin de la méthode. Nous avons choisi d’ajouter ces fonctionnalités car elles correspondent a celle proposée par CorbaTrace V1.0 mais pour les objets distants. L’appel de ces deux logs se fait, contrairement aux appels distants, par le développeur. En effet nous n’avons pas fait un intercepteur local au niveau de la machine JAVA pour récupérer tous les appels de méthode. Le programmeur devra utiliser la classe "CLogger" du package "corbaTrace.logger". Les deux appels sont :
- logCallBegin(String loggerName, Object src, Object dest, String method, String[] args)
loggerName : nom donné au logger, de type Sring.
src : objet source, celui qui appel la méthode, de type Objet .
dest : objet destination, celui sur qui l’appel est fait, de type Objet.
method : nom de la méthode appelée, de type String.
args : tableau d’arguments passés à la méthode.
- logCallEnd(String loggerName, Object src, Object dest,String method,
String result)
loggerName : nom donné au logger, de type Sring.
src : objet source, celui sur qui l’appel est fait, de type Objet.
dest : objet destination, celui qui appel la méthode, de type Objet.
method : nom de la méthode appelée, de type String.
result : resulat de l’appel de la méthode, de type String.
Pour la visualisation de ce type de message sur le diagramme de séquence nous suivrons la standardisation de l’OMG. Celle-ci consiste-en :

Cependant, comme c’est le développeur qui insère ces appels de log dans son programme, on ne pourra l’empêcher de ne loguer qu’une partie de l’appel de procédure; soit l’appel en tant que tel, soit uniquement le retour de la méthode.
Dans une prochaine version nous pourrions ajouter en plus du nom de la méthode le résultat de celle-ci. Nous ne l’avons pas fait pour ne pas surcharger le diagramme.
3.2.5
Début
et fin d’activité
Un autre type de log local est inclus dans CorbaTrace, il s’agit du début et fin d’activité. Il permet au développeur de signaler lorsqu’un processus débute son activité, et lorsqu'il la termine. Ceci est très utile car dans les applications réparties, il est courant de rencontrer de la programmation multi-processus. Le développeur peut ainsi surveiller l’état de ses processus pour confirmer le bon fonctionnement de son application. Comme pour l’appel de méthode, c’est le développeur qui doit indiquer dans son code ou commence et finit l’activité de son processus. Le programmeur devra utiliser la classe "CLogger" du package "corbaTrace.logger". Les deux appels sont :
- logActivityBegin(String loggerName, Object obj)
loggerName : nom donné au logger, de type String.
obj : l’objet qui commence son activité, de type Objet.
- logActivityEnd(String loggerName, Object obj)
loggerName : nom donné au logger, de type String.
obj : l’objet qui fini son activité, de type Objet.
Pour la visualisation de ce type de message sur le diagramme de séquence nous suivrons la standardisation de l’OMG. Celle-ci consiste-en :

Figure 10: diagramme de séquence avec début
et fin d’activité.
Étant donné que le développeur indique ces débuts et fins d’activité, on se rend vite compte que l’on pourra tomber dans des cas incohérents. En effet si le programmeur ne positionne pas bien ces logs ou n’en met pas le bon nombre, on va se trouver devant un diagramme qui ne reflètera pas la réalité. Voici un listing non exhaustif des cas qui posent problème :
Cas 1 : qu’un seul log de début ou de fin de méthode :
Figure
11: diagramme
de séquence avec qu’un seul début ou fin d’activité.

.
Dans ce cas, il n’y a qu’un seul début ou fin d’activité. On ne peut donc pas savoir quand commence ou fini le processus. La représentation comme elle est sur le diagramme de séquence est une représentation erronée de la réalité. Nous avons déduit qu’il finissait soit après la fin du diagramme ou commençait avant le début du diagramme.
Cas 2 : qu’un log de début ou de fin pour deux de début ou de fin:
Figure
12: diagramme
de séquence avec qu’un seul début ou fin d’activité pour deux fins ou
débuts d’activité.


Dans ce cas si le développeur indique un début ou fin d’activité pour deux fins ou débuts d’activités, l’information a affiché sera donc encore erroné. Nous avons relié tous les début et fin d’activité pour respecter les normes UML. Ceci est donc inconcevable.
Cas 3 : deux logs de débuts ou de fins pour deux de début ou de fin:
Figure 13: diagramme de séquence avec deux débuts ou fins
d’activité pour deux fins ou débuts d’activité

Dans ce cas une activité d’un processus est encapsulée dans une autre activité. Ceci est totalement impossible, nous ne pouvons donc pas nous permettre d’afficher une incohérence. Ces cas ne sont pas exhaustifs il en existe bien d’autres, mais nous n’allons pas tous les monter. Voici par contre un cas cohérent qui pourra être affiché.
Cas 4 : cohérence entre log de début et de fin d’activité:

Figure 14: diagramme de séquence cohérent pour les débuts et
fins d’activité
Dans ces deux cas Les débuts de fin d’activités sont cohérents. On peut aisément les afficher tout en étant quasiment sur de montrer au développeur ce qu’il attend. Pour tous les autres cas d’incohérence, nous avons choisi de lever une exception qui sera interceptée par l’interface graphique et qui affichera un message au développeur pour lui indiquer l’incohérence. Ensuite sur le diagramme, nous n’afficherons que les états cohérents. Nous aurions très bien pu afficher tous les états, même ceux incohérents, et laisser le développeur se rendre compte de l’incohérence et de modifier ses logs dans son application. Cependant nous pensons que ceci induirait le développeur en erreur. Qui plus est, notre souhait de respecter la norme UML n’aurait pas été exaucé.
3.2.6
Messages
de trace
Le dernier type de log local que nous avons ajouté à notre application CorbaTrace, est le message de trace. En effet lors du déboguage d’une application il est très souvent nécessaire de pouvoir afficher le contenu d’une variable à un endroit donné du programme. Plutôt que de faire un traditionnel "System.out" qui est vivement déconseillé, nous permettons au développeur de directement l’intégrer dans le diagramme de séquence par l’intermédiaire d’un log trace. Le programmeur utilisera la classe "CLogger" du package "corbaTrace.logger". L’appel est :
logTrace(String loggerName, Object obj, String message)
loggerName : nom donné au logger, de typa String
obj : objet dans lequel est appelée la méthode, de type Objet
message : message à afficher, de type String
La visualisation de ce type de log se fera par l’intermédiaire des commentaires en UML. Voici un exemple de ce type de log sur un diagramme de séquence :

Figure 15: diagramme de séquence avec un message trace
Dans ce dernier type de log il n’y a à priori pas d’incohérence possible. Par contre si le message est trop long à afficher, alors le diagramme peut devenir très vite illisible. Ce type de log doit être utilisé par le développeur uniquement pour des informations essentielles et pertinentes.
3.3 Messages Locaux
3.3.1
Description du
besoin
L’application CorbaTrace permet d’intercepter les communications Corba et de les visualiser. Ceci est très utile pour le déboguage des applications réparties. En effet, dans une application de ce type, il est très difficile de visualiser les traces qu’apporte un déboguage classique sur tous les objets distants.
L’intérêt des traces dans une application est de voir leur séquencement pour être sur que l’application fait bien ce que l’on veut. CorbaTrace permet de visualiser les appels de méthodes distants mais pas locaux. Ceci est donc une amélioration à ajouter aux fonctionnalités de CorbaTrace. Ainsi pour une application répartie, la visualisation des appels distants et des appels locaux sera possible. Ce qui fournira un outil performant et très utile à tous les développeurs d’application répartie. Pour la visualisation on ne distinguera pas un objet distant d’un objet local. Ce masque facilitera la visualisation des informations de déboguage. Comme nous vous l'avons décrit auparavant, les logs locaux sont de trois formes différentes. Les appels et retour de méthodes, les débuts et fins d’activités et les traces constituent les informations que peuvent décrire les logs locaux. Cet ensemble pourra être enrichi ultérieurement.
4 Synchronisation des messages
Pour commencer, il s’agit de resituer le problème de
la synchronisation. Sur un ORB, les objets sont distants, ce qui signifie que
rien ne garantit une horloge commune. Pour diverses raisons, les horloges
peuvent avoir des réglages différents (fuseaux horaires, mauvais réglage...).
Notre travail est donc d’estimer ce décalage d’horloge
entre les différents objets afin de mettre à jour les dates d’envoi et de
réception des messages et finalement d’obtenir ainsi une trace cohérente. Dans
la version 1.0 de CorbaTrace, une synchronisation a été réalisée (cf. 2.1.3),
et c’est celle-ci que nous reprenons et améliorons avant de l’intégrer dans la
version 2.0 .
4.1 Reprise de l’existant
De l’étude du
travail qui a déjà été fait, nous avons constaté plusieurs points intéressants:
Ø
Le code comporte
une structure de graphes tout à fait réutilisable et extensible à de
nouveaux traitements. Nous avons en effet une classe consacrée à la gestion des
graphes, utilisant deux classes pour les nœuds et les arcs. Le programme
principal se trouve dans la « classe Synchronizer » qui gère
l’ensemble du processus de synchronisation. Toutes les méthodes utiles au
traitement des informations dans les graphes ainsi que les techniques de
synchronisation existent déjà pour la plupart. Les choix de programmation ont
été suffisamment bien faits pour qu’il soit relativement simple de l’étendre à
de nouveaux traitements.
Ø
L’ensemble du code
est complet et fonctionnel.
Cependant, d’un point vue général, le code n’est pas
assez accessible; bien le comprendre et pouvoir le modifier pose des
nombreuses difficultés. C’est pourquoi il nous faut tout d’abord l’améliorer en
appliquant les techniques de refactoring.
4.2 Refactoring
Le refactoring est un procédé qui permet par
l’application de plusieurs règles relativement simples de reprendre du code
afin d’obtenir les critères d’une “bonne programmation”.
Nous recherchons surtout à le rendre plus clair et
accessible. Nous avons appliqué ces techniques aux classes “ObjectGraph”,
“ObjectGraphNode”, “ObjectGraphEdge” et “Synchronizer”.
Pour ces classes, on obtient ainsi notamment :
ü
des commentaires
en anglais plus explicites (et avec une meilleure orthographe)
ü
plus de
commentaires
ü
la séparation
des étapes de travail
ü
la décomposition
des méthodes (parfois trop longues)
ü
des noms de
méthodes ou d’attributs plus explicites
ü
un code plus
espacé, devenu beaucoup plus lisible
Une fois ce travail réalisé, il devient plus facile
pour nous de modifier le code, ainsi que pour les prochains programmeurs qui
souhaiteraient apporter leurs améliorations à notre code. Dès ce moment, le
travail le plus difficile commence, à savoir analyser le travail à effectuer et
l’effectuer, ce qui inclut des modifications à apporter et des extensions à
réaliser.
4.3 Analyse
Nous avons commencé par étudier la précédente
problématique. De cette étude est ressorti le fait que les hypothèses de départ
pouvaient être contestées.
En effet, contrairement à ce qui était énoncé, le temps d’un message apparaît sur un séquence de diagramme. L’échelle verticale représente le temps, ainsi on peut lire (ou faire apparaître) le temps d’un message.

Il n’est pas, également, aussi difficile que çà de
gérer du parallélisme dans les diagrammes de séquence en affichant des messages
croisés.

Nous arrivons cependant à une hypothèse de travail
commune : le temps d’un message peut être considéré comme nul, mais pour des
raisons différentes que nous justifions dans notre problématique.
Cette révision des hypothèses de travail implique
quelques bouleversements dans le processus de synchronisation à pondérer par le
fait que le code déjà existant est suffisamment complet et bien pensé pour
limiter l’étendue des modifications.
Il revient aussi d’intégrer le cas des logs
locaux : avec le processus de synchronisation que nous proposons, il
devient très simple de gérer ce cas particulier. En effet, quelque soient les
types de messages à traiter, nous mettons à jour les horloges de chaque objet;
ensuite il ne suffit plus qu’à mettre à jour les dates des messages (par
rapport aux horloges des objets émetteurs et receveurs). A priori, il ne
devrait pas y avoir de traitement particulier pour les messages locaux.
4.4 Problématique
Le temps de transmission d’un message (date arrivée - date départ) entre deux objets est composé du temps réel de parcours du message et du décalage des horloges des objets. Le temps de parcours d’un message est de l’ordre de la milliseconde ou de la seconde, alors que celui du décalage serait plutôt de la minute voire de l’heure. Le premier est donc négligeable devant de second. De plus entre deux objets le temps de parcours du message peut varier à tout moment (en raison du réseau) et est donc imprévisible, on ne peut donc pas se fier à lui pour nos calculs d’estimation. Nous allons donc considérer (comme dans la première version) que ce temps correspond uniquement au décalage des horloges locales.
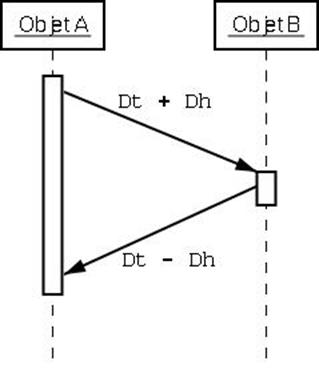
Figure 18: temps effectif idéal (mais non réel) d’un message
Sur ce schéma : « Dt » est le temps réel de
transmission du message et « Dh » le décalage entre les
horloges locales des objets A et B
Le cas présenté dans la figure 16 est utopique, et
nous ne considérons donc comme temps du message que le décalage entre les
horloges locales des objets A et B.
Compte tenu que nous souhaitons gérer au mieux le
parallélisme dans les envoies de messages entre objets distants, il nous faut
calculer le décalage d’horloge de chaque objet par rapport à un objet local
(toujours comme dans la première version) et appliquer ce décalage aux objets
(par une nouvelle technique).
4.5 Processus de synchronisation
Comme il est dit précédemment, nous devons
synchroniser les horloges locales des objets distants. Pour cela nous allons
calculer les décalages d’horloge de chaque objet. Une fois ce décalage calculé,
il s’agira de l’appliquer à chaque objet.
Ainsi nous avons juste à mettre à jour les dates d’envoi et de réception des messages en leur appliquant le décalage calculé dans le graphe pour les objets concernés (émetteur et récepteur des messages).
Le processus s’effectue toujours en trois étapes:
ü
ajout des
messages logués dans le graphe
ü
estimation des
décalages d’horloge
ü
mise à jour des
messages
Pour des raisons
pratiques, nous conservons une étape de séquentialisation des messages. En
effet, le tri des messages par leur date d’émission rend plus pratique leur
exploitation et affichage par l’API de visualisation SVG développée dans la
nouvelle version de CorbaTrace. Cette étape succède la mise à jour des
messages.
4.5.1 Ajout des messages logués dans le graphe
Cette étape a été particulièrement bien réussie dans
la première version. Nous nous contentons ici de rapidement la détailler afin
de bien comprendre l’ensemble du processus de synchronisation.
Pour plus de précisions, il est vivement conseillé de
consulter le rapport de l’année précédente.
Lorsque nous avons logué plusieurs messages entre
deux objets, on calcule le temps de message minimal Dmin, car c’est
celui qui approxime le mieux la différence réelle d’horloge entre les objets.Le
temps du message est calculé par soustraction de la date de départ de celle
d’arrivée. Si le résultat est positif, l’objet émetteur est en retard sur
l’objet receveur, alors que s’il est négatif, c’est le contraire (en avance).
Logiquement, le décalage des horloges dans l’autre sens (receveur vers
émetteur) est le temps opposé à celui déjà calculé.Ainsi on calcule le temps du
message et on crée un arc dans le graphe entre les deux objets concernés (deux
nœuds). Le poids de cet arc est le temps calculé (décalage entre les deux
horloges) et l’arc dans le sens
contraire possède un poids opposé au sien. Lorsque l’on a un autre message à
ajouter entre les mêmes objets, on calcule son temps et s’il est plus petit en
valeur absolue que le précédent (c’est le delta min), alors on le remplace
(mise à jour des poids des deux arcs entre les deux nœuds).
4.5.2 Estimation des décalages d’horloge
Cette étape est la plus technique du processus. Elle
s’inspire de procédés de synchronisation qui existent déjà.
A ce niveau du processus, nous possédons les
décalages estimés entre deux nœuds consécutifs. On souhaiterait maintenant
calculer tous les décalages par rapport à une horloge commune.
Pour cela, on considère un objet référence, et on calcule tous les décalages des autres horloges locales par rapport à la sienne. On sélectionne un objet référence par composante connexe (ou fortement connexe) dans le graphe. Le choix de cet objet référence n’est pas déterminant puisque quel qu’il soit le choix fait, le résultat final sera en principe le même. Nous avons tout de même garder le choix fait l’année dernière, c’est-à-dire choisir le nœud qui possède le plus d’arcs entrants et sortants comme nœud de référence.
“Le décalage minimal correspond à la somme des arcs
du plus long chemin.”
Il revient donc de mettre en place dans la classe “ObjectGraph” un algorithme de calcul de plus long chemin entre deux nœuds. Ensuite
il faudra appliquer cet algorithme à chaque nœud pour connaître son décalage
avec le nœud de référence.
Nous avons choisi un algorithme basé sur le modèle de
“PERT”. Dans ce genre d’algorithme, la difficulté est d’éviter les cycles. (en
théorie, le graphe ne doit pas en comporter). Il s’agit d’éviter les circuits
de poids infini.
Pour cela nous utilisons les marqueurs mis en place
et exploités dans la première version.
Description des étapes de réalisation et de
l’algorithme:
Ø
ajout d’un
attribut weightMax aux nœuds (classe ObjectGraphNode) pour stocker la valeur du plus long chemin entre le
nœud de référence et le nœud courant.
Ø
on initialise weightMax à “moins l’infini” (ou plutôt une forte valeur
négative) pour tous les nœuds
Ø
On part du nœud
de référence, on fixe son attribut weightMax
à zéro
Ø
pour chaque
voisin, on vérifie que (weightMax
du nœud courant + le poids de l’arc) < (weightMax du voisin), sinon on met ce dernier à jour avec (weightMax du nœud courant + le poids de l’arc)
Ø
on marque le
nœud courant
Ø
on recommence le
traitement avec le voisin s’il n’est pas marqué (ainsi on effectue un parcours
en largeur qui garantit de passer par tous les nœuds)
Ø
s’il reste des
nœuds non marqués (c’est le cas s’il y a plusieurs composantes connexes) on en
sélectionne un comme nœud de référence et on recommence l’opération
Après cela, chaque nœud contient le décalage de son
horloge avec celle du nœud de référence.
4.5.3 Mise à jour des messages
Tous les décalages sont maintenant calculés dans le
graphe, il ne reste plus qu’à mettre à jour les messages. Ceux-ci ont encore
des dates erronées à ce niveau du processus de synchronisation. Ce traitement
est relativement simple (particulièrement par rapport à l’ancien algorithme qui
effectuait nombre de calculs pour un résultat moins satisfaisant dans notre
problématique qui a d’autres exigences).
Pour chaque message, on identifie l’objet émetteur,
on récupère dans le graphe le décalage calculé et on l’applique à la date
d’émission du message. De même pour l’objet receveur du message.
A la suite de cette étape, tous les messages possèdent des dates d’envoi et de réception à jour.
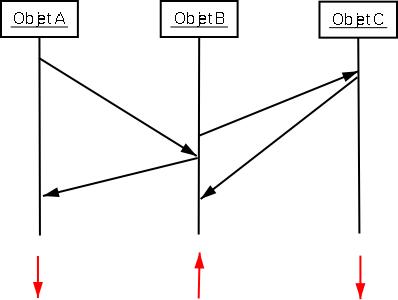
Figure 19:
décalages d’horloge à appliquer sur le diagramme de séquence

Figure 20:
décalages appliqués sur les objets du diagramme de séquence
Les dates des messages vont être mises à jour quelque
soientt le type des messages : locaux ou Corba (cf. Figure 19 et Figure 20).
Seul le cas des messages incomplets est plus particulier, car nous ne possédons qu’une seule date (celle d’envoi ou celle de réception). Dans ce cas, on applique la mise à jour de la date uniquement à l’objet connu (émetteur ou récepteur).
4.5.4 Limitations
Ce processus, s’il est bien appliqué, garantit une
bonne synchronisation des messages. Plus il y a d’échanges de messages et
d’informations à traiter, plus le résultat final sera précis et proche de la
réalité.
Cependant quelques cas exceptionnels peuvent
intervenir et ne seront jamais bien traités par notre synchronisation. Ainsi si
des horloges locales différentes avancent à des vitesses différentes, notre
algorithme est inefficace car il y aura des incohérences dans les temps des
messages. Par exemple, une horloge sera tantôt un retard par rapport à une
autre et tantôt en avance par rapport à cette même horloge.
4.5.5 Degré d’aboutissement
La synthèse du code est achevée et
fonctionnelle. Le code est désormais facile à faire évoluer.
Après avoir effectué de nombreux tests incluant
aussi bien les cas standards que les cas particuliers, il s’avère que la
synchronisation n’est pas encore pleinement satisfaisante. En effet, un cas
important à gérer est l’envoi de messages dans le passé, la cas où la date
d’envoie est plus récente que la date de réception en raison d’un décalage des
horloges des objets concernés, et ce cas n’est malheureusement pas encore géré.
Toutefois toutes les structures sont présentes pour
le gérer et je m’engage (Brice FRANCOIS) à mettre à jour la
synchronisation prochainement.
La synchronisation dans le cadre des cas généraux
est cependant satisfaisante. On peut visualiser les échanges de messages dans
le temps entre les objets distants.
Pour créer ses propres tests de synchronisation, il
suffit de modifier les fichiers XML de logs fusionnés.
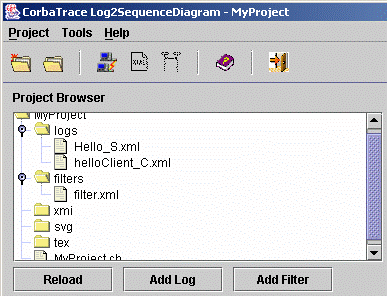
5 Interface graphique
L'un des
éléments manquants à CorbaTrace pour toucher un plus large public était une
interface graphique permettant de réaliser les principales actions du logiciel.
Parmi les
actions que nous souhaitions intégrer à l'interface graphique, nous pouvons
citer :
Ø
Lancer Log2SequenceDiagram à partir de l'interface après
avoir choisi les fichiers de log, le filtre et les options voulus
Ø
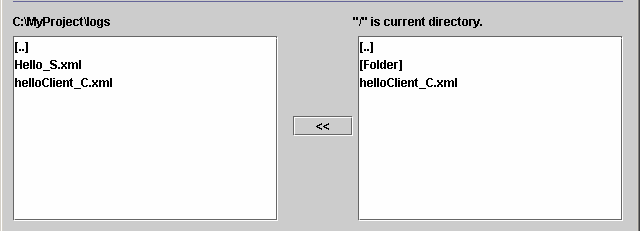
Récupérer via le protocole FTP les fichiers de log pouvant
se trouver sur des machines autres que la machine sur laquelle l'utilisateur se
trouve
Ø
Créer facilement des fichiers de filtre
Ø
Visualiser les diagrammes de séquence générés en SVG
5.1 Analyse - Choix technologiques
Le logiciel
CorbaTrace étant écrit en langage Java, nous nous sommes tournés pour
l'écriture de l'interface graphique vers l'API graphique de ce langage :
Swing[12].
L' Abstract
Window Toolkit (AWT) est historiquement la première bibliothèque graphique qui
fut proposé par Java. La contrainte de l'AWT est que Java fait appel au système
d'exploitation sous-jacent pour afficher les composants graphiques. Pour cette
raison, l'affichage de l'interface utilisateur d'un programme peut diverger
sensiblement : chaque système d'exploitation dessine à sa manière un bouton.
Or Java se veut
être 100% indépendant de la plate-forme utilisée! Pour cette raison, Swing fut
donc mis en place pour assurer 100% de portabilité. Ceci à cependant un coup
: pour assurer cette portabilité, un
composant graphique est dessiner non plus par le système mais par Java, ce qui
en terme de temps d'exécution à un prix.
Mais
l'avantage de Swing est de proposer des possibilités beaucoup plus étendues et
de nombreux widgets graphiques permettant la réalisation d'interfaces complexes
de manière relativement aisée.
L'interface
graphique est définie dans le package corbaTrace.gui, et peut être
représenté par le diagramme de classe UML suivant :
(Nb : afin de
ne pas surcharger ce diagramme, tous les attributs de classe correspondant aux
différents widgets graphiques tels que les boutons ne sont pas présents.)